
GLM-130B (ICLR 2023) is an open bilingual (English & Chinese) bidirectional dense model with 130 billion parameters, pre-trained using the General Language Model (GLM) algorithm1. It is designed to support inference tasks with the 130B parameters on a single A100 (40G * 8) or V100 (32G * 8) server. As of July 3rd, 2022, GLM-130B has been trained on over 400 billion text tokens (200B each for Chinese and English) and exhibits the following unique features:
- Bilingual: supports both English and Chinese.
- Performance (EN): better than GPT-3 175B davinci (+5.0%), OPT-175B (+6.5%), and BLOOM-176B (+13.0%) on LAMBADA and slightly better than GPT-3 175B (+0.9%) on MMLU.
- Performance (CN): significantly better than ERNIE TITAN 3.0 260B on 7 zero-shot CLUE datasets (+24.26%) and 5 zero-shot FewCLUE datasets (+12.75%).
- Fast Inference: supports fast inference on both SAT and FasterTransformer (up to 2.5X faster) with a single A100 server.
- Reproducibility: all results (>30 tasks) can be easily reproduced with open-sourced code and model checkpoints.
- Cross-Platform: supports training and inference on NVIDIA, Hygon DCU, Ascend 910, and Sunway.
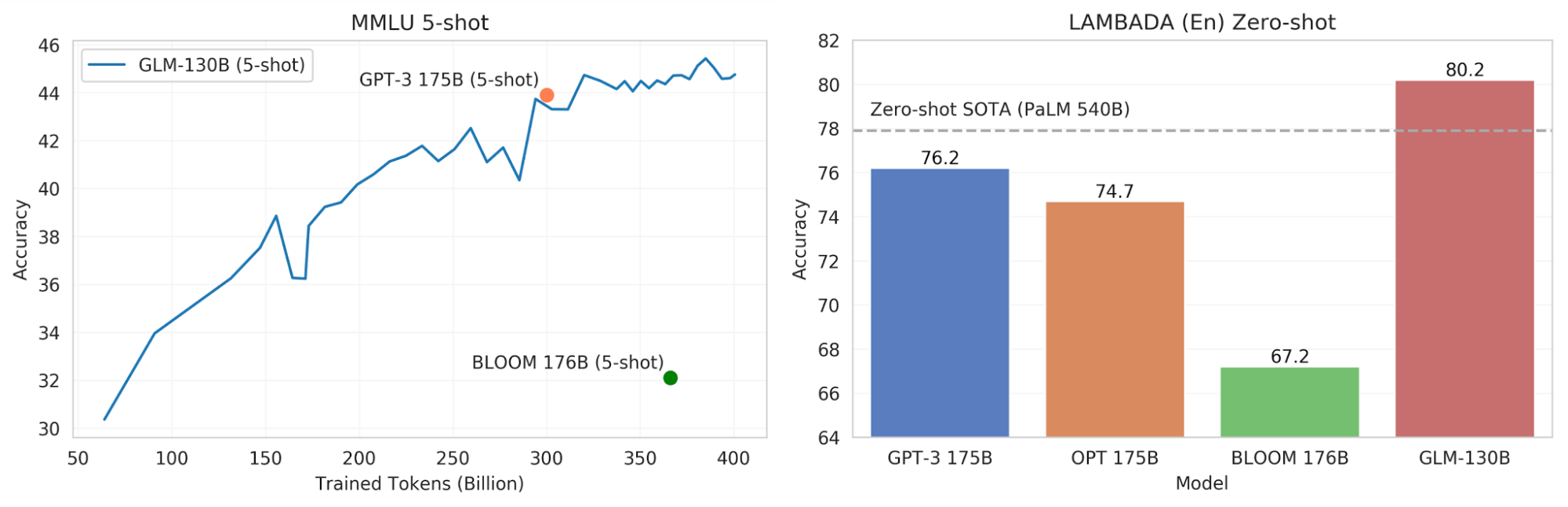
Figure 1. The performance of GLM-130B vs. models of similar scale on MMLU and LAMBADA. (Note that these are intermediate results and we have try our best to make fair evaluations and welcome everyone to join the efforts)
The model checkpoints of GLM-130B and code for inference are publicly available at our GitHub repo. The code for pre-training and fine-tuning as well as the research paper are coming soon.
Conceiving GLM-130B
The GLM-130B project was conceived in Dec. 2021 in a brainstorming meeting at Tsinghua KEG. We firmly believe that it is of value to pre-train a highly accurate language model, in particular for both Chinese and English. Though GPT-32 is the pioneer for this effort, it is not available to most people in the world. In addition, it supports English only. We therefore decide to initialize the project GLM-130B (code name “千亿”—the number 100B in Chinese). Please note that the WuDao 1.75T model we built last year is a sparse model with 480 mixture-of-experts (MoE), rather than a dense one as GPT-3. Our goal then is to train a bilingual pre-trained dense model with high accuracy on downstream tasks, and to make it open to everyone in the world-anyone, anywhere can download it and use it on a single server with appropriate GPUs.
The ambitious project soon faced several important challenges:
- Lack of computational resources: No organization is willing to sponsor such a big project and freely make it public.
- Lack of a robust pre-training algorithm: Despite GPT-3’s success on English corpus, it is unclear how to train a high-accurate bilingual model for both English and Chinese.
- Lack of fast inference solutions: Since the goal is to have the model public to everyone, we need to design fast inference solutions with low resource requirements to run the model.
For the pre-training algorithm, we finally chose GLM1 (ACL'22) due to its high performance in practice. We eventually decided to train a GLM model of 130 billion parameters after several rounds of discussions and exploration, because such a size makes it possible to run the inference on a single A100 (40G * 8) server.
Our first attempt at training the model was in January 2022, shortly after we received a small sponsor of GPUs for test running. However, we soon realized that we had significantly underestimated the technical difficulties of pre-training a model at such a scale (>100B). It seems that pre-training a highly accurate 100B-scale model is quite different from training a 10B-scale one. Due to frequent random hardware failures, model gradients exploding, unexpected excessive memory usage in the algorithm, debug for the 3D pipeline in the new Megatron and DeepSpeed frameworks, inability to recover from optimizer states, blocked TCP responses between processes, and many many unexpected “bugs”, the project was delayed for many times. The Tsinghua PACMAN team gave us a hand at this difficult time and together we successfully fixed most of the “bugs”.
By March, we were still short on computational resources, but fortunately got a chance to try test runs on several other platforms, including Ascend 910, Hygon DCU, NVIDIA, and Sunway. The immediate challenge was for us to adapt our training code to these different platforms, as the underlying operators are quite different. Also, it introduced many new issues: the element-wise operators not supporting fast computation for large-dimension vectors, various issues that hindered convergence—the large gradient norms of input embeddings, native Post-LN, Pre-LN3, and Sandwich-LN4, dataloader state seeds, and computation precision choices in Softmax and Attention — as well as numerous mistakes we ourselves made. With tremendous help from all of our generous partners, we finally succeeded in making our pre-training algorithms runnable across all the platforms—frankly, a surprising achievement for this project. The timeline of GLM-130B in Figure 2 covers most of the issues we have encountered and addressed as of this writing.
Figure 2. The timeline of major issues that training GLM-130B encountered and addressed, as of July 31st, 2022.
On April 26th, we received a generous computing sponsorship from Zhipu.AI — an AI startup that aims to teach machines to think like humans. After another week of testing, we finally kicked off the training of the GLM-130B model on its 96 A100 (40G * 8) servers on May 6th. Additionally, Zhipu.AI also sent a team to assist in evaluating the pre-trained model and help build a demonstration website.
The training period spanned two months, during which we began developing a program to perform inference tasks using the 130B model on only a single server with V100s (32G * 8). Though it is already the most accessible model of its scale, together with our partner from Tsinghua NLP (BMInf), we are currently exploring the possibility of using GLM-130B for inference on a single RTX-3090 server (24G * 8), which would truly make the 100B-scale model accessible to as many people as possible. We will continue to further reduce the resource requirements and keep the community updated on this important working item.
The Performance of GLM-130B
On July 3rd, 2022, the GLM-130B model had been trained on over 400 billion tokens and its few-shot performance reached and then surpassed the level of GPT-3 on the well-adopted Massive Multi-Task Language Understanding (MMLU) benchmark5 (Cf. Figure 1 (left) in the top of this blog). Specifically, the 5-shot performance of GLM-130B achieves an accuracy of 44.8% after viewing 400B (bilingual) tokens.
In addition to language understanding tasks, we have examined the language modeling capacity of GLM-130B on LAMBADA6, a challenging zero-shot last word prediction task that has been widely adopted in the evaluation of large-scale language models. Figure 1 (right) covers the zero-shot performance of related models (OPT7 and BLOOM’s intermediate results are taken from BLOOM’s eval repository). GLM-130B achieves an accuracy of 80.2% on zero-shot LAMBADA (En), while 76.2% for GPT-3 175B and 77.9% for the SOTA offered by PaLM 540B8.
As GLM-130B is a bilingual (English & Chinese) language model, we evaluate its zero-shot performance on two established Chinese NLP benchmarks—CLUE (Chinese Language Understanding Evaluation)9 and FewCLUE10. Note that downstream Chinese datasets are not included in the multi-task instruction pre-training. By comparing GLM-130B to the largest Chinese monolingual language model ERNIE 3.0 Titan 260B11, GLM-130B generates commanding results across all datasets.
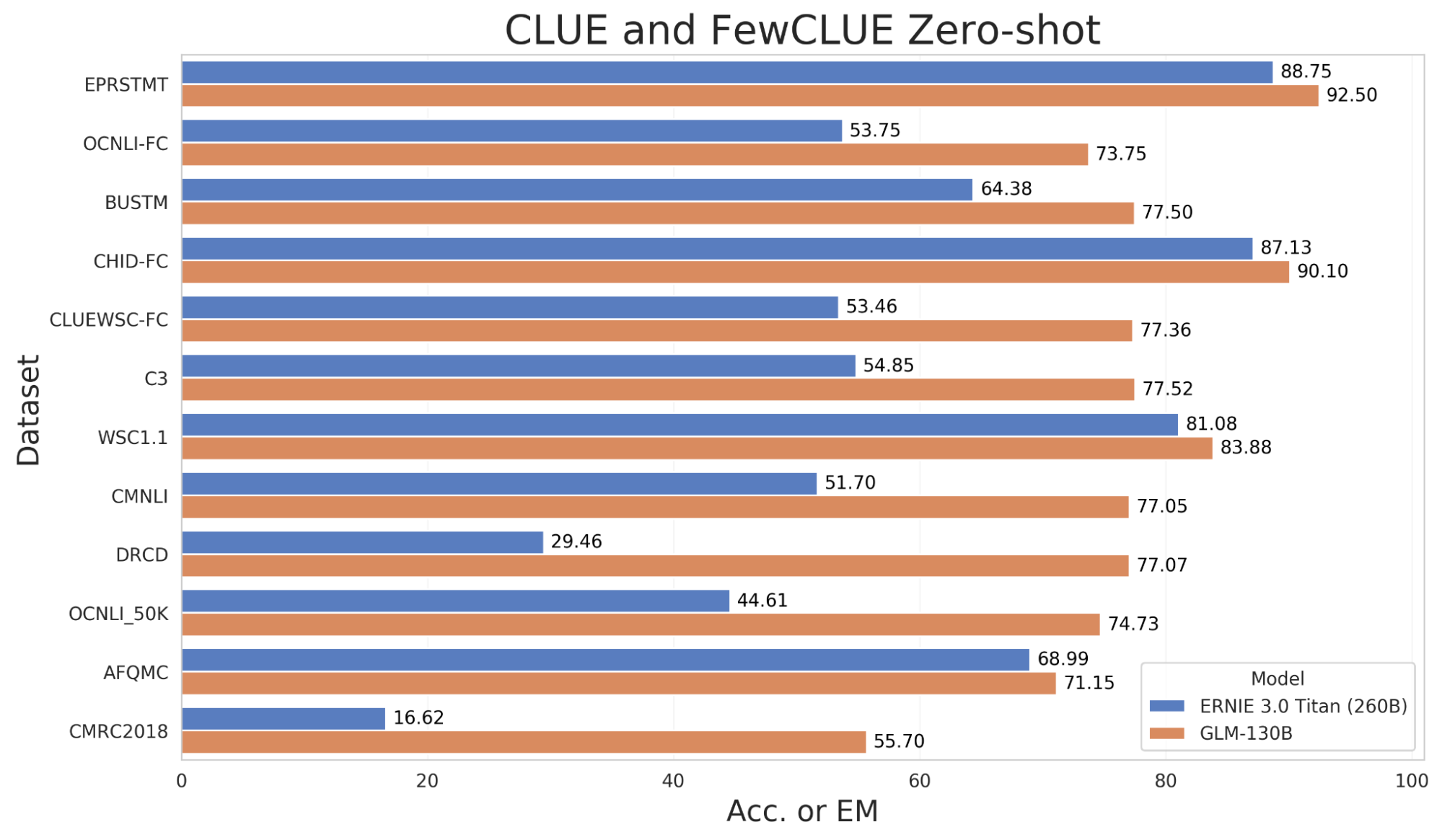
Figure 3. Zero-shot performance on part of CLUE and FewCLUE benchmark datasets.
Finally, we have been testing GLM-130B on a wide range of NLP tasks, including SuperGLUE12, Big-bench13, and so on. The results will be reported as the experiments proceed.
The GLM-130B Model
Now let us give a brief introduction to the techniques behind the GLM-130B model. More details and source code can be found at the our GitHub repo.
GLM-130B is a bilingual (English & Chinese) bidirectional language model with 130 billion parameters trained on over 400 billion text tokens. It is based on the General Language Model (GLM)1 architecture. GLM-130B leverages autoregressive blanking infilling as its primary pre-training objective. Taking the sentence in Figure 4 as an example, it masks random continuous spans (e.g., “complete unknown”) and predicts them autoregressively.

Figure 4. Example: How GLM-130B is pre-trained on “Like a complete unknown, like a rolling stone
In practice, GLM-130B uses two different mask tokens ([MASK] and [gMASK]) for short and long text generation, respectively. Additionally, it adopts the newly proposed techniques for the Transformer architecture, including the Rotary positional encoding (RoPE)14, DeepNorm15 layer normalization, and Gaussian Error GLU (GeGLU)16 17. All these designs contribute to this large-scale language model of 70 layers, 12,288 hidden state dimension, 2,048 maximum sequence length, and a bilingual tokenizer with 150,000 tokens based on icetk.
With this model architecture, GLM-130B is pre-trained on over 400 billion bilingual tokens (200B English and 200B Chinese tokens). Its pre-training objective consists of two parts. The first and primary (95%) part is the self-supervised pre-training that leverages autoregressive blank infilling over the public Pile18 corpora for English and several Chinese corpora. The second part (5%) is the multi-task instruction pre-training on a sampled subset of 70 different datasets from T0++19 and DeepStruct20, formatted in multi-task multi-prompted sequence to sequence generation with instructions. This design enables GLM-130B with strong capabilities to perform zero-shot learning over other datasets and zero-shot transfer from English to Chinese.
Finally, training GLM-130B has been a great challenge, whether from the perspective of research, engineering, hardware, deployment, and computation resources. Over the course of the hardware and model testing, training, and evaluation, the student leaders of the GLM-130B team—Aohan Zeng and Xiao Liu—took tremendous efforts with many sleepless nights dedicated to making this project survive and eventually succeed under various pressures. Kudos to Aohan, Xiao, the team, and our generous GPU sponsors.
Future Work
GLM-130B is still under development, and we are inviting users and collaborators around the world to join its open community to push the boundary of large pre-trained models and artificial intelligence. Currently, we are working on the following directions:
- Continual Training of GLM-130B. Large language models are recently known to be insufficiently trained21. According to Chinchilla’s estimation, the optimal number of training tokens for a 130B language model should be about 4.0T, which is 10 times larger than what we have done. We are looking for sponsors and computing platforms to support the ambitious goal of GLM-130B’s following training.
- INT8 quantization. GLM-130B is trained with FP16 precision, a total of 260G of GPU memory is required to store the full model weights. The DGX-A100 server with 320G (40G * 8) GPU memory can host GLM-130B well. However, the price of the A100 is still unaffordable for many academic users. We are working on INT8 quantization on the GLM-130B model to reduce the inference memory requirements, making it possible to run GLM-130B on servers with smaller GPU memory (e.g., 8 * RTX 3090 GPU)
- Mixture-of-Experts (MoE) Scaling. Mixture-of-Experts have been shown to be an effective method for scaling model parameters22 23, however, the MoE models do not perform as well as dense models of the same scale. Our previous work—WuDao 1.75T—is based on a 4.8B dense model, and it is extended with 480 experts to 1.75 trillion parameters. Based on our high-performance dense model GLM-130B with 130B parameters, we are trying to scale it up to reach trillions or even ten trillions of parameters for higher accuracy by using Mixture-of-Expert tools such as FastMoE24 and its optimized version FasterMoE.
- Parameter-Efficient P-Tuning. Despite large language models’ superior zero-shot and few-shot ability, tuning them on downstream datasets can further boost their performance on specific tasks. However, their outrageous number of parameters cause great redundancy and cost in fine-tuning. Based on our previous work P-Tuning25 and P-Tuning v226, we endeavor to exploit the downstream performance of GLM-130B with parameter-efficient transfer learning.
Acknowledgements
This project is supported by the National Science Foundation for Distinguished Young Scholars (No. 61825602).
Lead Contributors
Aohan Zeng (Tsinghua KEG), Xiao Liu (Tsinghua KEG)
Contributors
Tsinghua KEG — the Knowledge Engineering Group at Tsinghua
Zhengxiao Du, Ming Ding, Qinkai Zheng, Hanyu Lai, Zihan Wang, Zhuoyi Yang, Jifan Yu, Xiaohan Zhang, Wendi Zheng, Xiao Xia, Yifan Xu, Weng Lam Tam, Yuxiao Dong, Jie Tang
Tsinghua PACMAN — the Parallel Architecture & Compiler technology of Mobile, Accelerated, and Networked systems Group at Tsinghua
Zixuan Ma, Jiaao He, Zhenbo Sun, Jidong Zhai, Wenguang Chen
Tsinghua NLP (BMInf) — the Natural Language Processing Group at Tsinghua
Guoyang Zeng, Xu Han, Weilin Zhao, Zhiyuan Liu
Zhipu.AI — an AI startup that aims to teach machines to think like humans
Yufei Xue, Shan Wang, Jiecai Shan, Haohan Jiang, Zhengang Guo, Peng Zhang
Computation Sponsor
Project Leader
Jie Tang (Tsinghua KEG & BAAI)
-
Du, Zhengxiao, Yujie Qian, Xiao Liu, Ming Ding, Jiezhong Qiu, Zhilin Yang, and Jie Tang. “GLM: General Language Model Pretraining with Autoregressive Blank Infilling.” In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 320-335. 2022. ↩︎ ↩︎ ↩︎
-
Brown, Tom, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Kaplan, Prafulla Dhariwal, Arvind Neelakantan et al. “Language models are few-shot learners.” Advances in neural information processing systems 33 (2020): 1877-1901. ↩︎
-
Xiong, Ruibin, Yunchang Yang, Di He, Kai Zheng, Shuxin Zheng, Chen Xing, Huishuai Zhang, Yanyan Lan, Liwei Wang, and Tieyan Liu. “On layer normalization in the transformer architecture.” In International Conference on Machine Learning, pp. 10524-10533. PMLR, 2020. ↩︎
-
Ding, Ming, Zhuoyi Yang, Wenyi Hong, Wendi Zheng, Chang Zhou, Da Yin, Junyang Lin et al. “Cogview: Mastering text-to-image generation via transformers.” Advances in Neural Information Processing Systems 34 (2021): 19822-19835. ↩︎
-
Hendrycks, Dan, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. “Measuring Massive Multitask Language Understanding.” In International Conference on Learning Representations. 2020. ↩︎
-
Paperno, Denis, Germán Kruszewski, Angeliki Lazaridou, Quan Ngoc Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernández. “The LAMBADA dataset: Word prediction requiring a broad discourse context.” arXiv preprint arXiv:1606.06031 (2016). ↩︎
-
Zhang, Susan, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan et al. “Opt: Open pre-trained transformer language models.” arXiv preprint arXiv:2205.01068 (2022). ↩︎
-
Chowdhery, Aakanksha, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham et al. “Palm: Scaling language modeling with pathways.” arXiv preprint arXiv:2204.02311 (2022). ↩︎
-
Xu, Liang, Hai Hu, Xuanwei Zhang, Lu Li, Chenjie Cao, Yudong Li, Yechen Xu et al. “CLUE: A Chinese Language Understanding Evaluation Benchmark.” In Proceedings of the 28th International Conference on Computational Linguistics, pp. 4762-4772. 2020. ↩︎
-
Xu, Liang, Xiaojing Lu, Chenyang Yuan, Xuanwei Zhang, Huilin Xu, Hu Yuan, Guoao Wei et al. “Fewclue: A chinese few-shot learning evaluation benchmark.” arXiv preprint arXiv:2107.07498 (2021). ↩︎
-
Wang, Shuohuan, Yu Sun, Yang Xiang, Zhihua Wu, Siyu Ding, Weibao Gong, Shikun Feng et al. “Ernie 3.0 titan: Exploring larger-scale knowledge enhanced pre-training for language understanding and generation.” arXiv preprint arXiv:2112.12731 (2021). ↩︎
-
Wang, Alex, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. “Superglue: A stickier benchmark for general-purpose language understanding systems.” Advances in neural information processing systems 32 (2019). ↩︎
-
Pettee, Mariel, Chase Shimmin, Douglas Duhaime, and Ilya Vidrin. “Beyond imitation: Generative and variational choreography via machine learning.” arXiv preprint arXiv:1907.05297 (2019). ↩︎
-
Su, Jianlin, Yu Lu, Shengfeng Pan, Bo Wen, and Yunfeng Liu. “Roformer: Enhanced transformer with rotary position embedding.” arXiv preprint arXiv:2104.09864 (2021). ↩︎
-
Wang, Hongyu, Shuming Ma, Li Dong, Shaohan Huang, Dongdong Zhang, and Furu Wei. “Deepnet: Scaling transformers to 1,000 layers.” arXiv preprint arXiv:2203.00555 (2022). ↩︎
-
Hendrycks, Dan, and Kevin Gimpel. “Gaussian error linear units (gelus).” arXiv preprint arXiv:1606.08415 (2016). ↩︎
-
Dauphin, Yann N., Angela Fan, Michael Auli, and David Grangier. “Language modeling with gated convolutional networks.” In International conference on machine learning, pp. 933-941. PMLR, 2017. ↩︎
-
Gao, Leo, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang et al. “The pile: An 800gb dataset of diverse text for language modeling.” arXiv preprint arXiv:2101.00027 (2020). ↩︎
-
Sanh, Victor, Albert Webson, Colin Raffel, Stephen Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin et al. “Multitask Prompted Training Enables Zero-Shot Task Generalization.” In The Tenth International Conference on Learning Representations. 2022. ↩︎
-
Wang, Chenguang, Xiao Liu, Zui Chen, Haoyun Hong, Jie Tang, and Dawn Song. “DeepStruct: Pretraining of Language Models for Structure Prediction.” In Findings of the Association for Computational Linguistics: ACL 2022, pp. 803-823. 2022. ↩︎
-
Hoffmann, Jordan, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas et al. “Training Compute-Optimal Large Language Models.” arXiv preprint arXiv:2203.15556 (2022). ↩︎
-
Fedus, William, Barret Zoph, and Noam Shazeer. “Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity.” Journal of Machine Learning Research 23, no. 120 (2022): 1-39. ↩︎
-
Zoph, Barret, Irwan Bello, Sameer Kumar, Nan Du, Yanping Huang, Jeff Dean, Noam Shazeer, and William Fedus. “Designing effective sparse expert models.” arXiv preprint arXiv:2202.08906 (2022). ↩︎
-
He, Jiaao, Jiezhong Qiu, Aohan Zeng, Zhilin Yang, Jidong Zhai, and Jie Tang. “Fastmoe: A fast mixture-of-expert training system.” arXiv preprint arXiv:2103.13262 (2021). ↩︎
-
Liu, Xiao, Yanan Zheng, Zhengxiao Du, Ming Ding, Yujie Qian, Zhilin Yang, and Jie Tang. “GPT understands, too.” arXiv preprint arXiv:2103.10385 (2021). ↩︎
-
Liu, Xiao, Kaixuan Ji, Yicheng Fu, Zhengxiao Du, Zhilin Yang, and Jie Tang. “P-tuning v2: Prompt tuning can be comparable to fine-tuning universally across scales and tasks.” arXiv preprint arXiv:2110.07602 (2021). ↩︎