
GLM-130B (ICLR'23) 是一个开源开放的双语(中文和英文)双向稠密模型,拥有 1300 亿参数,模型架构采用通用语言模型(GLM1)。它旨在支持在一台 A100(40G * 8) 或 V100(32G * 8)服务器上对千亿规模参数的模型进行推理。截至 2022 年 7 月 3 日,GLM-130B 已完成 4000 亿个文本标识符(中文和英文各 2000 亿)的训练,它有以下独特优势:
- 双语:同时支持中文和英文。
- 高精度(英文): 在 LAMBADA 上优于 GPT-3 175B davinci(+4.0%)、OPT-175B(+5.5%)和 BLOOM-176B(+13.0%),在 MMLU 上略优于 GPT-3 175B(+0.9%)。
- 高精度(中文):在 7 个零样本 CLUE 数据集(+24.26%)和 5 个零样本 FewCLUE 数据集(+12.75%)上明显优于 ERNIE TITAN 3.0 260B。
- 快速推理:支持用一台 A100 服务器使用 SAT 和 FasterTransformer 进行快速推理(提速最高可达 2.5 倍)。
- 可复现性:所有结果(超过 30 个任务)均可通过我们的开源代码和模型参数轻松复现。
- 跨平台:支持在 NVIDIA、Hygon DCU、Ascend 910 和 Sunway 处理器上进行训练与推理。
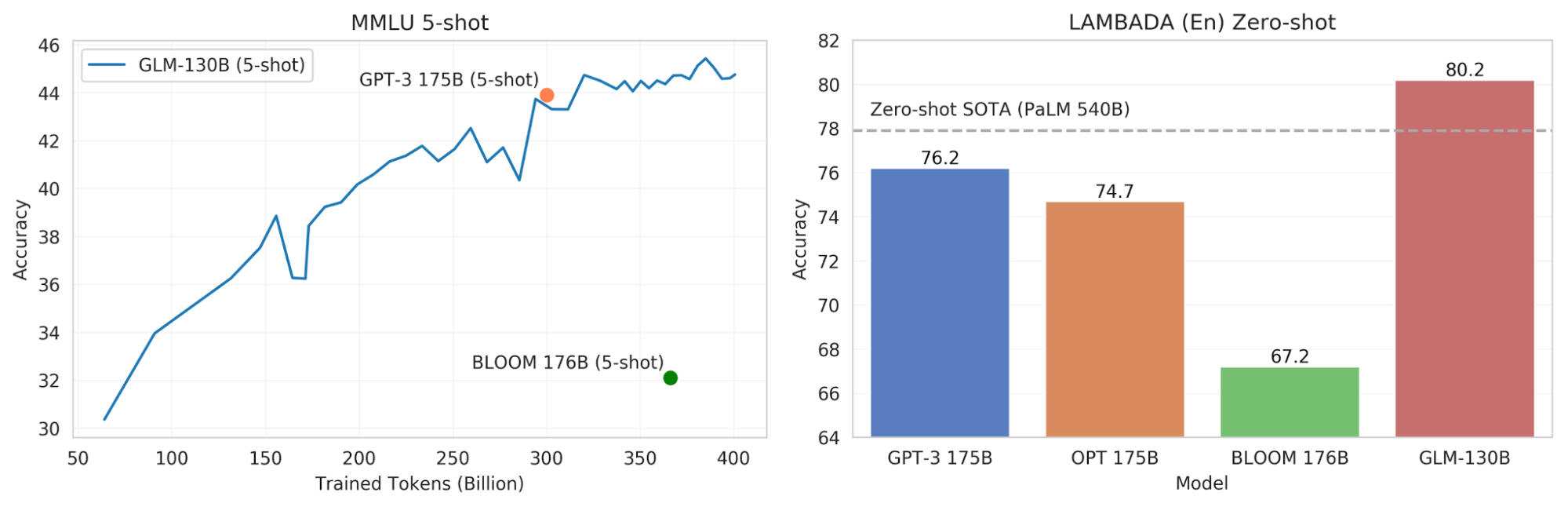
图 1. GLM-130B 的任务表现:与 MMLU 和 LAMBADA 上类似规模的模型相比。(请注意,目前这些均为中间结果,我们尽力做出公平的评估,并欢迎大家一起参与评估。)
GLM-130B 模型和推理代码在我们的 GitHub 仓库 公开提供。预训练和微调的代码以及研究论文即将发布。
GLM-130B:构思
2021 年 12 月,在清华大学知识工程实验室的一次内部头脑风暴会上,我们提出了 GLM-130B 项目的雏形。当时,我们的想法是预训练一个高精度的双语模型(中文/英文),并将其免费开放出来。一来是目前大模型的研究看起来还比较“空中楼阁”,很多研究员都由于缺少算力没法使用,甚至很多企业都用不上;另一方面目前高质量的模型都很少开源开放。GPT-32 是大模型的先驱,但其模型不支持对外开放,而且它也不支持中文。需要注意的是,我们的目标是训练一下1300亿参数(项目代号 “千亿”)的稠密模型,而去年我们研发的“悟道1.75T模型”是一个含 480 个专家混合(MoE)的稀疏模型。我们的理想是世界上任何一个人都可以免费下载千亿模型,并在一台低配的 GPU 服务器上就可以使用它。
然而,我们很快就面临诸多挑战:
- 缺乏计算资源:很难有机构愿意赞助如此大花费的项目,并免费将其公开。
- 缺乏高质量的预训练算法:针对双语的高质量预训练算法还有待验证和提升。
- 缺乏快速推理方法:快速推理方法是保证模型能在低配GPU服务器上运行起来的基础,也是让每个人都能用得上千亿大模型的关键。
对于预训练模型架构算法,我们选择了我们实验室在 21 年提出的 GLM1(ACL'22)模型,其在多个任务上表现出了不俗的性能。然后经过几轮激烈的争论,我们最终决定训练一个 1300 亿参数的 GLM 模型。一来千亿稠密模型能保证高精度,另一方面这个规模还可以在一台 A100 服务器上就进行单机推理。
2022 年 1 月,我们得到了一个 GPU 服务商的小型赞助,开始了我们的第一次测试运行。然而,我们很快发现我们之前大大低估了千亿模型训练的技术难度。预训练一个高精度的千亿模型与训练百亿模型完全不同:频繁的随机硬件故障、模型梯度爆炸、算法中意外的过多内存使用、新的 Megatron 和 DeepSpeed 框架中 3D 流水线的调试、无法从优化器状态中恢复、机器间 TCP 拥塞,以及许多许多意外的 “bug”,项目被多次推迟。清华 PACMAN 团队在这段困难时期向我们伸出了援手,我们一起成功地修复了大部分的 “bug”。
到了 3 月份,我们仍然缺少充足的计算资源,幸运的是我们得到了在其他几个平台上进行测试的机会,包括Ascend 910、Hygon DCU、NVIDIA 和神威。但是直接的难题是我们需要把训练代码适配到这些不同的平台,因为它们的底层算子各不相同(而且很多算子还有所欠缺)。这期间也引入了许多新的技术问题:不支持大维度向量快速计算的 Element-wise 算子,以及阻碍收敛的各种问题——输入嵌入层的过大梯度,Post-LN、Pre-LN3 和Sandwich-LN4 的不稳定性,Dataloader 状态种子恢复,以及 Softmax 和 Attention 的计算精度选择——当然还包括我们自己犯的种种错误。幸运地是,在所有热心合作伙伴的大力帮助下,我们最终能够在所有平台(Ascend 910、Hygon DCU、NVIDIA 和神威)成功运行GLM千亿预训练算法——对我们团队来说,这虽意味着很多个不眠之夜,却也的确是一个意外的收获(跨平台能力)。图 2 中的 GLM-130B 时间轴,涵盖了截至目前我们所遇到和解决的大部分问题。

图 2. 截至2022年7月31日,训练GLM-130B遇到和解决的主要问题的时间轴
4 月 26 日,我们得到了来自 Zhipu.AI(智谱AI——一家旨在“让机器像人一样思考”的人工智能初创公司)慷慨的计算资源赞助。经过又一个星期的测试,我们终于从 5 月 6 日开始在其支持的 96 台 A100(40G*8)服务器上启动了 GLM-130B 模型的训练。此外,智谱还派出了一个工程师团队,协助评估预训练模型,并帮助建设演示网站。
整个训练过程横跨两个月,在此期间,我们开始考虑训练完成后的推理解决方案,并在一台 V100(32G * 8)服务器上实现了合理速度的 130B 模型推理。目前,我们正与清华 NLP 实验室的 BMInf 团队一起探索在一台 RTX-3090 服务器(24G * 8)上使用 GLM-130B 推理的可能性,实现这一目标将可以使更多人用得起千亿模型。
GLM-130B:任务表现
截至 2022 年 7 月 3 日,GLM-130B 模型已经在超过 4000 亿个文本标识符上进行了训练,其少样本学习的性能在多任务语言理解基准(MMLU)5 上达到并超过了 GPT-3 的水平(参见博客顶部的图 1(左))。GLM-130B 的 5 样本学习性能在训练了 4000 亿个(双语)文本标识符后能达到 44.8% 的准确率。
除了语言理解任务外,我们还在被广泛用于大规模语言模型性能评估的 LAMBADA6 基准上考察了 GLM-130B 的语言建模能力。。图 1(右)展示了相关模型的零样本性能(OPT7 和 BLOOM 的中间结果取自 BLOOM 的评估库)。令人可观的是,GLM-130B 在 LAMBADA(En)上达到了 80.2% 的准确率,而 GPT-3 175B 为 76.2%,此前最好结果为 PaLM 540B的 77.9%8。
由于 GLM-130B 是一个双语(英文和中文)语言模型,我们还在两个中文 NLP 基准上评估它的零样本性能,即 CLUE9 和 FewCLUE10。值得注意的是,中文的下游数据集并不包括在多任务预训练中。GLM-130B 相比目前最大的中文语言模型 ERNIE 3.0 Titan 260B11,在所有数据集上都产生了更好的表现。
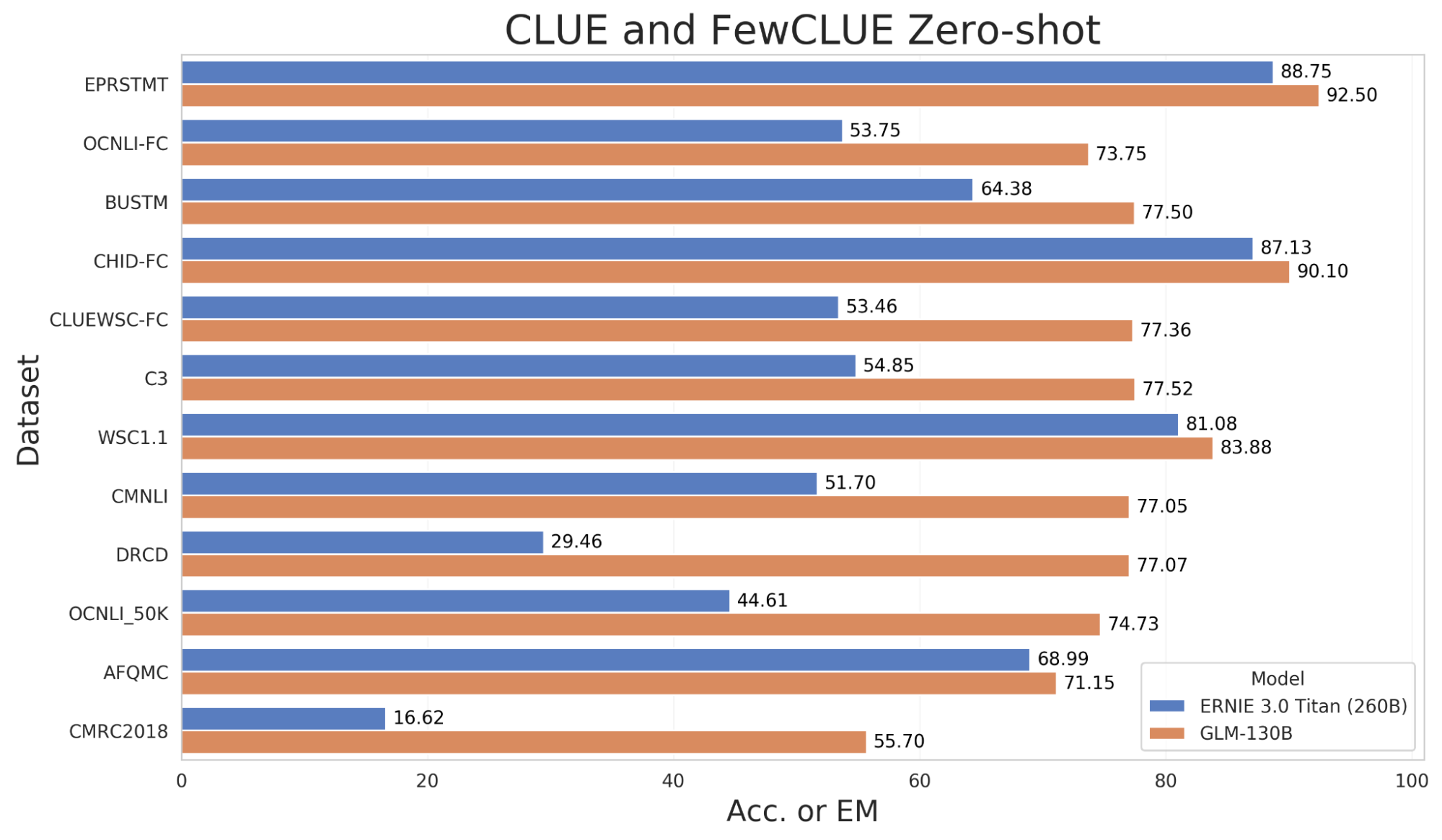
图 3. GLM-130B 在部分 CLUE 和 FewCLUE 基准数据集的零样本性能。
最后,我们仍在继续对 GLM-130B 进行广泛的下游任务测试,包括 SuperGLUE12、Big-bench13 等等。我们将随着实验的进行及时与大家分享相应结果。
GLM-130B:模型
在这一部分,我们将简单介绍一下 GLM-130B 模型背后的技术。更多的细节和源代码可以在项目的 GitHub 仓库 中找到。
GLM-130B 是一个 1300 亿参数规模的双语(中文和英文)双向语言模型。它的底层架构是基于通用语言模型(GLM1),在超过 4000 亿个文本标识符上预训练完成。GLM-130B 利用自回归空白填充作为其主要的预训练目标,以图 4 中的句子为例,它掩盖了随机的连续文本区间(例如,“complete unkown”),并对其进行自回归预测。

图 4. 例子:GLM-130B 在语料“Like a complete unknown, like a rolling stone”进行自回归填空预训练
在实际训练中,GLM-130B 使用两种不同的掩码标识符([MASK] 和 [gMASK]),分别用于短文和长文的生成。此外,它还采用了最近提出的旋转位置编码(RoPE)14、DeepNorm15 层规范化和高斯误差 GLU(GeGLU)16 17 技术。所有这些设计和技术都对 GLM-130B 大规模语言模型的稳定训练和高精度性能有所帮助。具体来说,GLM-130B 模型含有 70 层 Transformer,隐层维度 12,288,最大序列长度 2,048,以及一个基于 icetk 的 150,000 个标识符的双语分词器。
GLM-130B 对超过 4000 亿个双语标记(2000 亿英文和 2000 亿中文标记)进行了预训练。它的预训练目标由两部分组成:第一部分(95%)是自监督的预训练,即在公开的大规模语料库以及其他一些较小的中文语料库上的自回归空白填充。第二部分(5%)是在 T0++18 和 DeepStruct19 中 70 个不同数据集的抽样子集上进行多任务指令预训练,格式为基于指令的多任务多提示序列到序列的生成。这种设计使 GLM-130B 可以在其他数据集上进行了零样本学习,以及从英文到中文的零样本迁移。
回顾千亿项目的过程,无论从研究、工程、硬件、部署和计算资源的角度,我们都能深刻体会到训练 GLM-130B 其实是一个巨大的挑战,项目中间也面临多次中断的可能。幸运地是,在硬件和模型的测试、训练和评估过程中,GLM-130B 团队尤其是学生负责人——曾奥涵和刘潇同学——付出了巨大的努力,在各种压力下夜以继日地致力于使这个项目存活并最终坚持到取得一定成果。最后,我们向为 GLM-130B 项目提供 GPU 算力支持的赞助商们表示诚挚的谢意。
下一步工作
GLM-130B 的研发仍在继续进行中。与此同时,我们邀请大家加入它的开放社区,推动大规模预训练模型的发展。目前,我们正专注于以下几个方向的研究:
- GLM-130B 的进一步训练:最近的研究表明,大规模语言模型通常训练不足20。根据Chinchilla 的估计,一个 130B 语言模型的最佳训练标识符训练量应该是 4.0T 左右,比我们目前所训练的数量要大 10 倍。我们正在寻找赞助商和计算平台来支持 GLM-130B 的进一步训练。
- INT8 量化:GLM-130B 以 FP16 精度进行训练,总共需要 260G 的 GPU 内存来存储模型权重。DGX-A100 服务器提供了 320G 的 GPU 内存,所以可以天然地支持 GLM-130B。然而,A100 的价格对于绝大多数研究者来说仍然是无法承担的。我们正在对 GLM-130B 模型进行 INT8 量化,以减少推理内存的需求,从而使 GLM-130B 有可能在具有较小 GPU 内存的服务器上运行(例如 8 卡 RTX 3090 GPU)。
- 混合专家(MoE)方法以扩展模型规模:混合专家模型(Mixture-of-Experts, MoE)已被证明是扩展模型参数的有效方法21 22,然而,MoE模型在相同规模下的表现并不如稠密模型好。我们之前的工作——“悟道1.75T”在基于4.8B的稠密模型,将专家数量扩展到480个以达到1.75万亿的参数。我们正在尝试基于 MoE 技术对 GLM-130B 进行模型扩展,如通过 FastMoE23 及其加速版本 FasterMoE 来进一步扩大它的参数规模,以达到数万亿甚至百万亿规模的参数量,从而获得更高的性能表现。
- 参数高效 P-Tuning:尽管大规模语言模型具有卓越的零样本和少样本学习能力,通过在下游数据集上对它们进行调整可以进一步提升在特定任务上的性能。然而,它们数量庞大的参数在微调中面临巨大的参数冗余和计算成本。基于我们以前的工作 P-Tuning24 和 P-Tuning v225,我们正在努力尝试将这些技术应用到 GLM-130B 中,以实现参数高效的迁移学习。
致谢
这一项目由国家自然科学基金杰出青年科学基金项目(No. 61825602)支持。
学生负责人
曾奥涵(清华大学计算机系知识工程实验室),刘潇(清华大学计算机系知识工程实验室)
技术贡献
清华大学计算机系知识工程实验室 — the Knowledge Engineering Group at Tsinghua
杜政晓,丁铭,郑勤锴,赖瀚宇,汪子涵,杨卓毅,于济凡,张笑涵,郑问迪,夏箫,徐逸凡,谭咏霖,东昱晓,唐杰
清华大学计算机系 PACMAN 实验室 — the Parallel Architecture & Compiler technology of Mobile, Accelerated, and Networked systems Group at Tsinghua
马子轩,何家傲,孙桢波,翟季冬,陈文光
清华大学计算机系自然语言处理实验室(BMInf) — the Natural Language Processing Group at Tsinghua
曾国洋,韩旭,赵威霖,刘知远
智谱AI — an AI startup that aims to teach machines to think like humans
薛宇飞,王山,陕杰才,姜皓瀚,郭振钢,张鹏
Computation Sponsor
项目总负责
唐杰(清华大学计算机系知识工程实验室 & 北京智源人工智能研究院)
-
Du, Zhengxiao, Yujie Qian, Xiao Liu, Ming Ding, Jiezhong Qiu, Zhilin Yang, and Jie Tang. “GLM: General Language Model Pretraining with Autoregressive Blank Infilling.” In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 320-335. 2022. ↩︎ ↩︎ ↩︎
-
Brown, Tom, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Kaplan, Prafulla Dhariwal, Arvind Neelakantan et al. “Language models are few-shot learners.” Advances in neural information processing systems 33 (2020): 1877-1901. ↩︎
-
Xiong, Ruibin, Yunchang Yang, Di He, Kai Zheng, Shuxin Zheng, Chen Xing, Huishuai Zhang, Yanyan Lan, Liwei Wang, and Tieyan Liu. “On layer normalization in the transformer architecture.” In International Conference on Machine Learning, pp. 10524-10533. PMLR, 2020. ↩︎
-
Ding, Ming, Zhuoyi Yang, Wenyi Hong, Wendi Zheng, Chang Zhou, Da Yin, Junyang Lin et al. “Cogview: Mastering text-to-image generation via transformers.” Advances in Neural Information Processing Systems 34 (2021): 19822-19835. ↩︎
-
Hendrycks, Dan, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. “Measuring Massive Multitask Language Understanding.” In International Conference on Learning Representations. 2020. ↩︎
-
Paperno, Denis, Germán Kruszewski, Angeliki Lazaridou, Quan Ngoc Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernández. “The LAMBADA dataset: Word prediction requiring a broad discourse context.” arXiv preprint arXiv:1606.06031 (2016). ↩︎
-
Zhang, Susan, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan et al. “Opt: Open pre-trained transformer language models.” arXiv preprint arXiv:2205.01068 (2022). ↩︎
-
Chowdhery, Aakanksha, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham et al. “Palm: Scaling language modeling with pathways.” arXiv preprint arXiv:2204.02311 (2022). ↩︎
-
Xu, Liang, Hai Hu, Xuanwei Zhang, Lu Li, Chenjie Cao, Yudong Li, Yechen Xu et al. “CLUE: A Chinese Language Understanding Evaluation Benchmark.” In Proceedings of the 28th International Conference on Computational Linguistics, pp. 4762-4772. 2020. ↩︎
-
Xu, Liang, Xiaojing Lu, Chenyang Yuan, Xuanwei Zhang, Huilin Xu, Hu Yuan, Guoao Wei et al. “Fewclue: A chinese few-shot learning evaluation benchmark.” arXiv preprint arXiv:2107.07498 (2021). ↩︎
-
Wang, Shuohuan, Yu Sun, Yang Xiang, Zhihua Wu, Siyu Ding, Weibao Gong, Shikun Feng et al. “Ernie 3.0 titan: Exploring larger-scale knowledge enhanced pre-training for language understanding and generation.” arXiv preprint arXiv:2112.12731 (2021). ↩︎
-
Wang, Alex, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. “Superglue: A stickier benchmark for general-purpose language understanding systems.” Advances in neural information processing systems 32 (2019). ↩︎
-
Pettee, Mariel, Chase Shimmin, Douglas Duhaime, and Ilya Vidrin. “Beyond imitation: Generative and variational choreography via machine learning.” arXiv preprint arXiv:1907.05297 (2019). ↩︎
-
Su, Jianlin, Yu Lu, Shengfeng Pan, Bo Wen, and Yunfeng Liu. “Roformer: Enhanced transformer with rotary position embedding.” arXiv preprint arXiv:2104.09864 (2021). ↩︎
-
Wang, Hongyu, Shuming Ma, Li Dong, Shaohan Huang, Dongdong Zhang, and Furu Wei. “Deepnet: Scaling transformers to 1,000 layers.” arXiv preprint arXiv:2203.00555 (2022). ↩︎
-
Hendrycks, Dan, and Kevin Gimpel. “Gaussian error linear units (gelus).” arXiv preprint arXiv:1606.08415 (2016). ↩︎
-
Dauphin, Yann N., Angela Fan, Michael Auli, and David Grangier. “Language modeling with gated convolutional networks.” In International conference on machine learning, pp. 933-941. PMLR, 2017. ↩︎
-
Sanh, Victor, Albert Webson, Colin Raffel, Stephen Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin et al. “Multitask Prompted Training Enables Zero-Shot Task Generalization.” In The Tenth International Conference on Learning Representations. 2022. ↩︎
-
Wang, Chenguang, Xiao Liu, Zui Chen, Haoyun Hong, Jie Tang, and Dawn Song. “DeepStruct: Pretraining of Language Models for Structure Prediction.” In Findings of the Association for Computational Linguistics: ACL 2022, pp. 803-823. 2022. ↩︎
-
Hoffmann, Jordan, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas et al. “Training Compute-Optimal Large Language Models.” arXiv preprint arXiv:2203.15556 (2022). ↩︎
-
Fedus, William, Barret Zoph, and Noam Shazeer. “Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity.” Journal of Machine Learning Research 23, no. 120 (2022): 1-39. ↩︎
-
Zoph, Barret, Irwan Bello, Sameer Kumar, Nan Du, Yanping Huang, Jeff Dean, Noam Shazeer, and William Fedus. “Designing effective sparse expert models.” arXiv preprint arXiv:2202.08906 (2022). ↩︎
-
He, Jiaao, Jiezhong Qiu, Aohan Zeng, Zhilin Yang, Jidong Zhai, and Jie Tang. “Fastmoe: A fast mixture-of-expert training system.” arXiv preprint arXiv:2103.13262 (2021). ↩︎
-
Liu, Xiao, Yanan Zheng, Zhengxiao Du, Ming Ding, Yujie Qian, Zhilin Yang, and Jie Tang. “GPT understands, too.” arXiv preprint arXiv:2103.10385 (2021). ↩︎
-
Liu, Xiao, Kaixuan Ji, Yicheng Fu, Zhengxiao Du, Zhilin Yang, and Jie Tang. “P-tuning v2: Prompt tuning can be comparable to fine-tuning universally across scales and tasks.” arXiv preprint arXiv:2110.07602 (2021). ↩︎